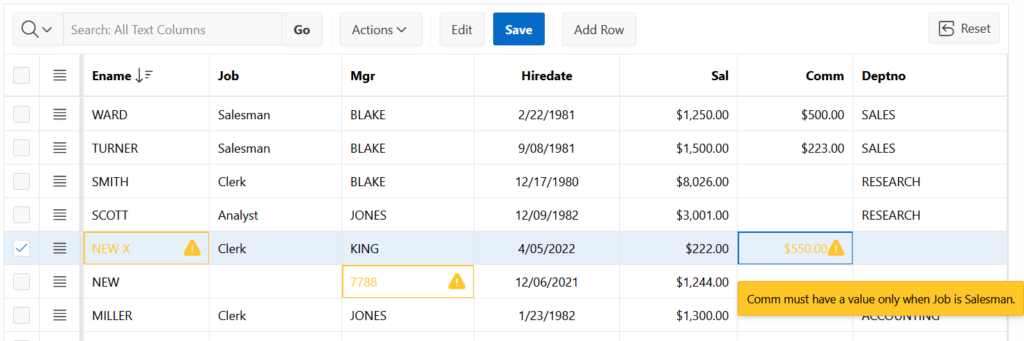
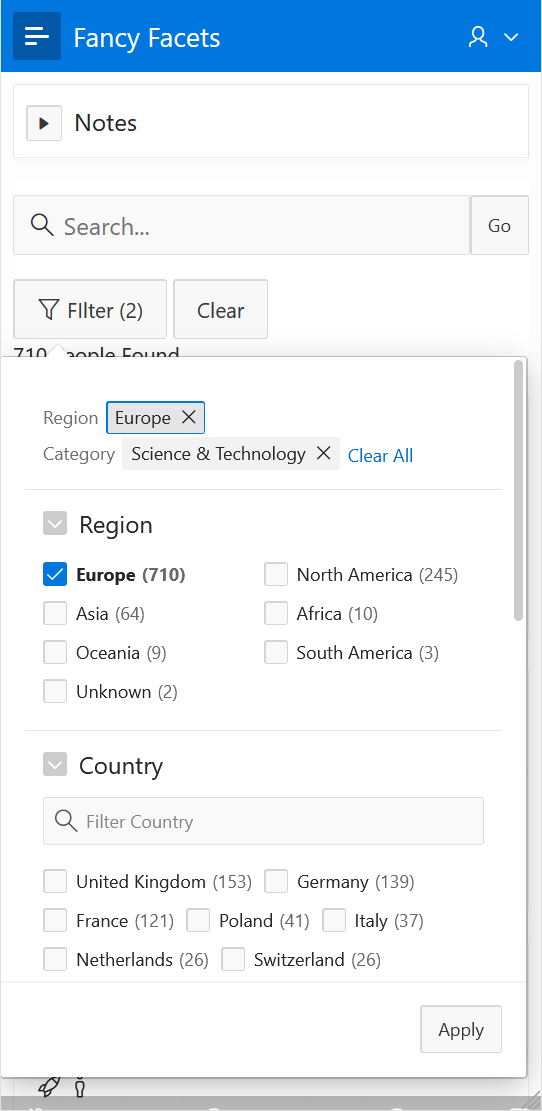
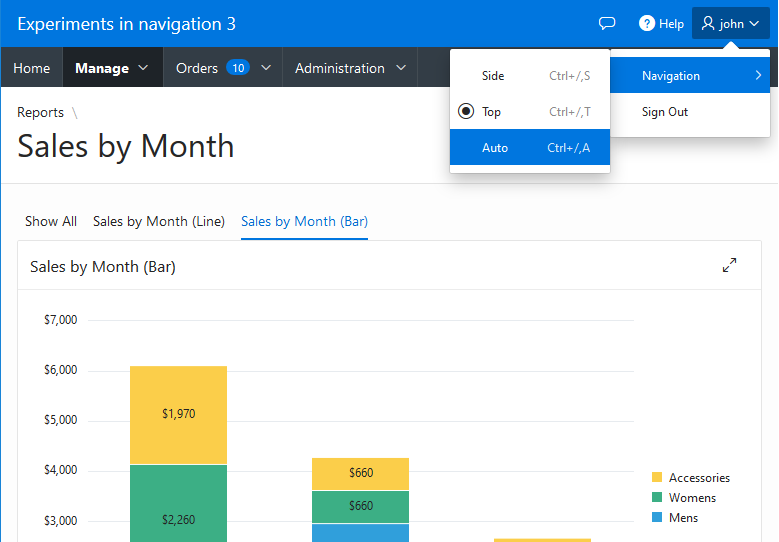
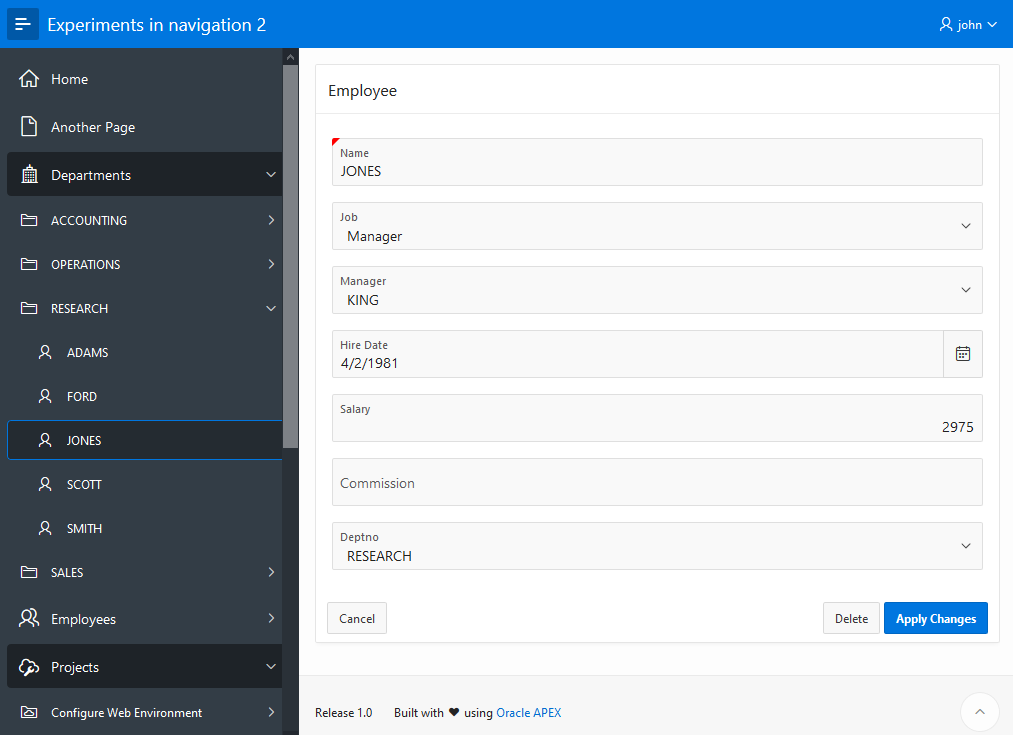
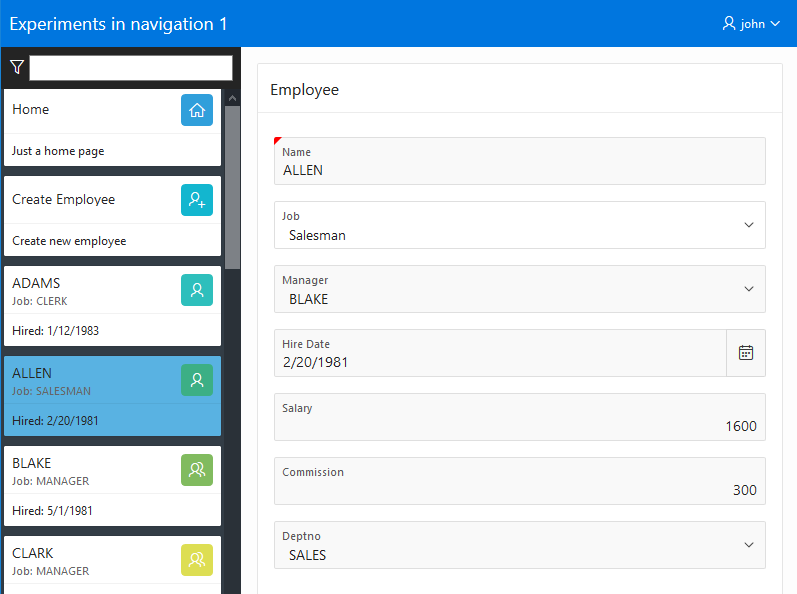
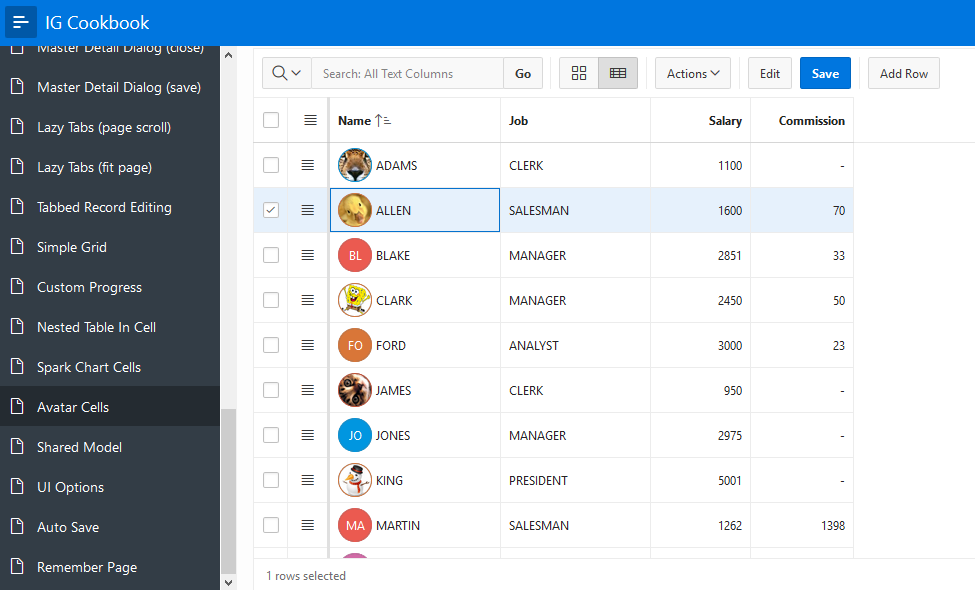
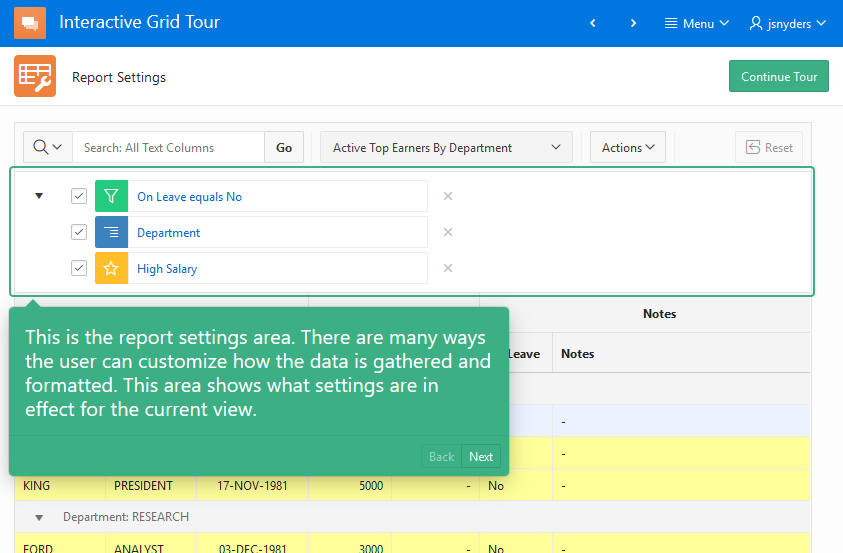
Yay APEX 22.1 is released! There are plenty of great new features. One of my favorites is the Region Sort Page Item. Something that doesn’t get a lot of attention is new functionality in the APIs. So I have created a demo app that shows what can be done with some of these new JavaScript APIs.
If you emphasize the “low” in low-code then this article may not be for you. On the other hand if you like to know how a little code can enable exceptional use cases read on. The raw info on what is new for APIs can be found in the release notes and the details can be found in the JavaScript API Reference but examples can give a better idea how these things can be put to use.
This is not a tutorial or deep explanation of every new API. It is a sample APP. To get anything out of it you will need to download the New API Features 22.1 app and read through the notes (click Notes link in top banner) on each page and also the code comments. If you haven’t installed APEX 22.1 yet you can use apex.oracle.com. First install the tables needed by this APP. Install Sample Interactive Grids app to get the EBA_DEMO_IG_PEOPLE and EBA_DEMO_IG_EMP tables. This will be fun because you get to use the new App Gallery. From SQL Workshop Utilities/Sample Datasets install Tasks Spreadsheet to get the EBA_TASKS_SS table.
Reminder: Any forward looking statements I make in this blog or the sample app is just my opinion not an official statement of product direction.
Comments closed